1、审题
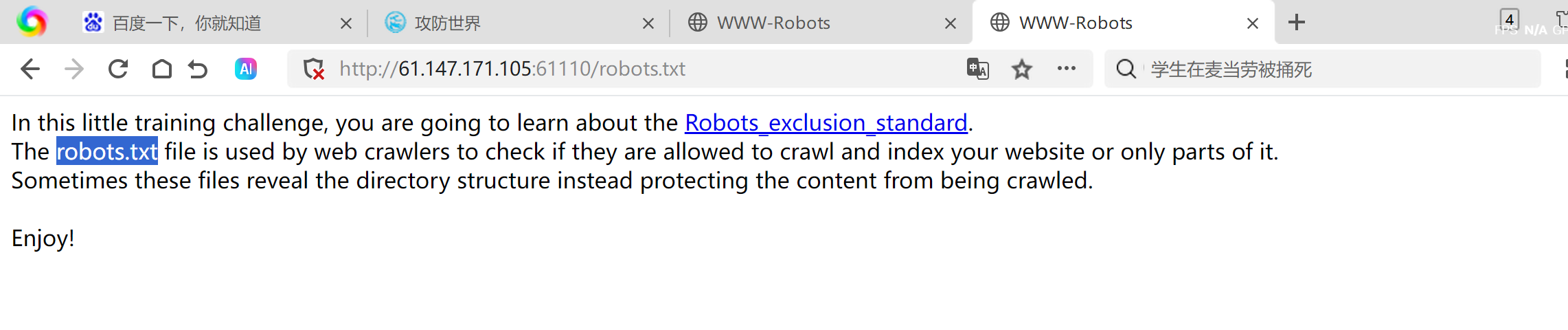
出现英文提示。翻译过后的结果为
在这个小小的训练挑战中,你将学习关于机器人排除标准(Robots_exclusion_standard)的知识。
robots.txt文件被网络爬虫用来检查它们是否被允许抓取和索引你的网站或仅部分网站。
有时这些文件会揭示目录结构,而不是保护内容不被抓取。
2、解题
1.1
61.147.171.105:61110/robots.txt

发现关键路径f10g.php
1.2

访问该路径得到flag
1
| cyberpeace{9a3413a1d8cb372b9359b5ebcd4c5f5e}
|





